PipeOnline 2.0: Automated EST Processing and Functional Data Sorting
ARTICLE
Ayoubi P, Jin X, Leite S, Liu X, Martajaja J, Abduraham A, Wan Q, Yan W, Misawa E and Prade R 2002 PipeOnline 2.0: Automated EST Processing and Functional Data Sorting Nucleic Acid Research 30: 4761-4769
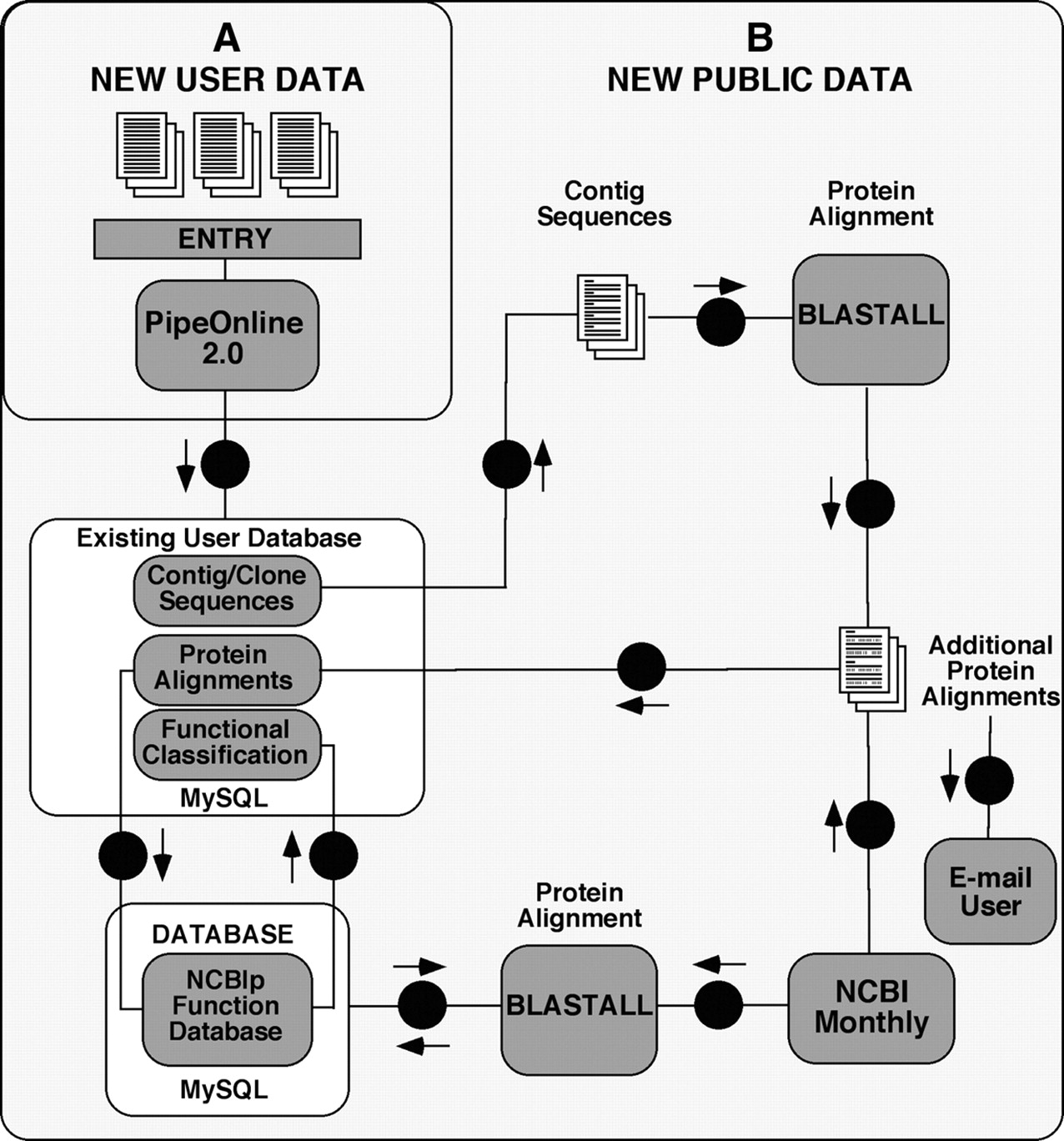
Expressed sequence tags (ESTs) are generated and deposited in the public domain, as redundant, un-annotated, single-pass reactions, with virtually no biological content. PipeOnline automatically analyses and transforms large collections of raw DNA-sequence data from chromatograms or FASTA files by calling the quality of bases, screening and removing vector sequences, assembling and rewriting consensus sequences of redundant input files into a unigene EST data set and finally through translation, amino acid sequence similarity searches, annotation of public databases and functional data. PipeOnline generates an annotated database, retaining the processed unigene sequence, clone/file history, alignments with similar sequences, and proposed functional classification, if available. Functional annotation is automatic and based on a novel method that relies on homology of amino acid sequence multiplicity within GenBank records. Records are examined through a function ordered browser or keyword queries with automated export of results. PipeOnline offers customization for individual projects (MyPipeOnline), automated updating and alert service.